J’ai dit ça à une amie et elle m’a demandé de développer. J’ai répondu en disant qu’on peut faire l’analogie entre la vie en France et ce qui se passe en ce moment sur les quais des gares TGV. Comme je prends le TGV tous les jeudis et les vendredis en ce moment, je vois ce qui se passe et ça fait réfléchir.
En ce moment, pour prendre son train, il faut
présenter le bon billet,
porter un masque,
présenter le pass sanitaire (ou un test PCR négatif).
Tout est très réglementé, très strict, même si pas dans les formes : le personnel dit gentiment bonjour à tout le monde, y compris à celles et ceux qu’il va rembarrer… La courtoisie est une « externalité positive », diraient les économistes : bien qu’elle soit là surtout pour préserver le bien-être des personnes qui remplissent les critères d’éligibilité et facilitent le travail des agents, elle est finalement là pour tout le monde ; du moins, sa première formule l’est. Car la réglementation est stricte et ne prévoit en principe aucune autre « passerelle » aux personnes qui ne sont pas en mesure de la respecter.
Si je connais la réglementation et possède tout ce qu’il faut pour la respecter, la voie est libre. Si en revanche je n’ai pas l’ensemble des trois articles réglementaires, je ne peux pas prendre mon train. Le temps d’aller me procurer ce qui me manque peut me faire louper le train. Auquel cas reprendre un autre (comme préparer une reconversion professionnelle) nécessite du temps et de l’argent pour tenir bon.
À ceci près qu’au bout d’un moment, soit il n’y a plus aucun train, soit il est trop tard pour aller où je comptais aller.
J’ai alors le choix entre
renoncer,
emprunter une voie marginale, comme faire du stop (avec la précarité et les risques que cela implique).
En ces temps de crise, 4 leçons de management pour une vie professionnelle réussie, méditez ces 4 leçons:
– Communication – Procédures – Hiérarchie – Gestion des affaires
1. Communication
Un homme entre dans la douche au moment précis où sa femme en sort, lorsque la sonnerie retentit à la porte de leur maison. La femme s’enroule dans une serviette de toilette, descend les escaliers en courant et va ouvrir la porte d’entrée. C’est Laurent, le voisin de palier. Avant qu’elle n’ait pu dire un mot, il lui lance : « Je te donne 500 EUR immédiatement si tu laisses tomber ta serviette ». Elle réfléchit à toute vitesse et décide de laisser choir la serviette. Il l’admire un bon moment, puis lui tend un billet de 500 EUR. Un peu étonnée, mais contente de la petite fortune qu’elle vient de se faire en un clin d’½il, elle remonte dans la salle de bain. Son mari, encore sous la douche, lui demande : « C’était qui ? » « C’était Laurent « « Super, il t’a rendu les 500 EUR qu’il me devait ? »
Morale n°1 : Si vous travaillez en équipe, partagez rapidement les informations concernant les dossiers communs, vous éviterez ainsi bien des malentendus désagréables.
2. Procédures
Au volant de la 2 CV, un prêtre raccompagne une nonne au couvent. Le prêtre ne peut s’empêcher de regarder ses superbes jambes croisées. Il pose subitement la main droite sur la cuisse de la nonne. Elle le regarde et lui dit : »Mon père, vous souvenez-vous du Psaume 129 ? » Penaud, le prêtre : Psaume 129 ? » Il rougit une fois de plus et retire sa main, balbutiant une excuse. Les voilà arrivés au couvent. La nonne descend de la voiture sans dire un mot. Le prêtre pris de remords pour son geste déplacé se précipite sur la Bible, à la recherche du Psaume 129. Psaume 129: « Allez de l’avant, cherchez toujours plus haut, vous trouverez la gloire »
Morale n°2 : Au travail, une bonne connaissance des procédures est recommandée pour atteindre les objectifs …
3. Hiérarchie
Un commercial, une secrétaire et un DRH sortent du bureau à midi et marchent vers un petit restaurant lorsqu’ils trouvent, sur un banc, une vieille lampe à huile. Ils la frottent et un génie s’en échappe. « D’habitude, j’accorde trois souhaits, mais comme vous êtes trois, vous n’en aurez qu’un chacun ». La secrétaire bouscule les deux autres en gesticulant : » A moi, à moi ! Je veux être sur une plage des Bahamas, en vacances perpétuelles, sans aucun des soucis qui pourraient empêcher de profiter de la vie » Et pouf, elle disparaît. Le commercial s’avance à son tour : « A moi, à moi ! Je veux siroter une pina Colada sur une plage de Tahiti avec la femme de mes rêves ! » Et pouf, il disparaît. « C’est à toi » dit le génie en regardant le directeur du personnel. « Je veux que ces deux cons soient de retour au bureau après la pause déjeuner…. »
Morale n°3 : En règle générale, laissez toujours les chefs s’exprimer en premier.
4. Gestion des affaires
A la ferme, le cheval est malade. Le vétérinaire dit au paysan : » Je lui injecte un remède, si dans trois jours il n’est pas remis, il faudra l’abattre. » Le cochon qui a tout entendu, dit au cheval: « Lève toi ! » Mais le cheval est trop fatigué. Le deuxième jour le cochon dit : « Lève toi vite ! » Le cheval est toujours aussi fatigué. Le troisième jour le cochon dit : « Lève toi sinon ils vont t’abattre ! » Alors dans un dernier effort, le cheval se lève. Heureux, le paysan dit : « Faut fêter ça: on tue le cochon ! »
Morale n°4 : Il faut toujours s’occuper de ses affaires. Et surtout … fermer sa gueule !
The main challenge, the so-called “golden rule” for BI- and Data Sciences-oriented degrees, is undeniably to train professionals that will be sought-after in the job market. Choosing the right IT tools to teach is one of the key factors , especially given there is a whole lot of choice out there: there is exotic software of which you can’t tell whether it is here to stay or should probably be used with caution; old software —perhaps too old for some— but which have been tried and tested over time; commercial software, both expensive and lousy or user-unfriendly, but which is nevertheless widespread, even ubiquitous and which, as a result —and against all logic,— manages to make itself count; free and open-source software, some of which highly appreciable, and yet they only enjoy a small market share amongst businesses. Overwhelmed with this wide range of choices, and having, in addition, to comply with bureaucracy and various budgetary and legal constraints, academics have to address the dilemma between the aforementioned goal on the one hand —which is to teach students software that is popular with businesses— with, on the other hand, the other purpose of universities as centres of excellence and temples of knowledge, which is to spread knowledge, good practices and the best methods resulting from the latest research.
In this essay, after we refer to two sources to present businesses’ actual preferences when it comes to BI and data sciences software and programming languages, we will then see how the sacrosanct “golden rule” has been being either drawn on certain occasions —e. g. to account for an unfair and anti-competitive “partnership” concluded in plain sight between the State administrations and one of the infamously aggressive commercial software vendors— or violated on other occasions, against all logic. To whose advantage? Well, the same ones’, it seems.
Knowing what companies want
Ricco Rakotomalala is rather well-known on the Web: academic and, since 2013, head of the Master SISE at the University Lyon 2, —a master’s degree which has its own YouTube channel, created in 2015, “Lyon Data Science,” which is pretty interesting,— also creator of free and open-source data mining teaching software (SIPINA, TANAGRA) and author of many tutorials and DRM-free ebooks.
In a January 2018 YouTube videodealing with teaching R and Python in Data Science degrees, Mr. Rakotomalala gives a lecture of more than one and a half hours which sprang up as a result of “an in-depth reflection on the key characteristics that teaching software should have”. The first of these characteristics is the “golden rule” which we have already presented in the introduction above.
The software taught in university courses must be that actually used in companies or, at the very least, resemble them.
The rationale behind this rule is clear: young graduates must be trained in the tools used by companies likely to hire them. So, how can we find out what companies want?
KDnuggets.com
For a modest university with a local scope, it is enough for its heads to get this kind of information from local companies; and even if their degree will quickly end up being locked into totally abusive “partnerships” with Microsoft, SAS or IBM, well, that’s how it goes: when you have to straddle the fence and regularly account for the budget granted to you by the State with decent hiring rates, all means are good.
Another idea may be to consult the results of a specialized survey, a complementary and thought-provoking source of information, especially if the survey covers other highly “computerized” countries of the world. One of the surveys on statistical analysis software and languages has been conducted every year in May for the past twenty years by the site KDnuggets.com. In his January 2018 video, Mr. Rakotomalala compares the results of 2017 (it will be 2019 for us) to those of 2005 and makes a few comments (listen to his explanations in the video of his conference, starting at 33:27):
https://www.kdnuggets.com/polls/2005/data_mining_tools.htm R, although not number one in the ranking, is extremely popular, including from Mr. Rakotomalala’s personal experience: most of the traffic drawn to his personal website consists of people coming for his R course materials and exercises. R has made an impressive climb in this ranking moving up from the bottom to second place (of the 2017 ranking). The speaker finds R’s evolution remarkable, which distinguishes it from other open-source statistical analysis tools that had the same genesis but remained on the margin: this was notably the case of open-source software of which Mr. Rakotomalala was the creator for one (TANGRA) and the contributor for the other (SIPINA). “R was devised as an open-source tool for academic research from the very beginning… In fact, there’s a NYTimes story [from 2009] that explains the origin of R, with Ross Ihaka and [Robert] Gentleman, where they explain the path and all that… it’s an academic work. I could have done the same thing. The key element is that this tool started being used by companies.” (48:23)
The evolution of the Python language has been even more impressive: more popular than R, more popular than anything else data sciences-related, Python has dominated this ranking for a few years now, while in 2005 this scripting language wasn’t even part of it.
We should also note that Excel was a sufficient piece of software for statisticians in the 1990s and 2000s and that it remained a must-have in 2005 (3rd place in the ranking). Today, however, although still a must-have (4th place), this software is no longer sufficient: there’s way too much data now to fit on a spreadsheet, the systems are interconnected and web-oriented, and many procedures are automated. One tool of choice in classical statistical studies, Excel is of no use in data sciences or machine learning.
r4stats.com
In order not to limit ourselves to the only argument of authority that are the results of the KDnuggets.com survey, here is another one: that of the r4stats.com blog: a personal (and presumably independent) site whose “mission is twofold:
to analyze the world of data science,
and to help people learn to use R,” —in a world dominated by the “big three” commercial software packages: SAS by SAS Institute, SPSS by IBM and Stata by StataCorp.
The author of this blog, created in 2012, is Bob Muenchen, an American university professor who
handles the research software contracts for The University of Tennessee (information provided in response to one of the blog readers);
is familiar with R as well as the aforementioned commercial software as he is the author of “R for SAS and SPSS Users” and “R for Stata Users” textbooks.
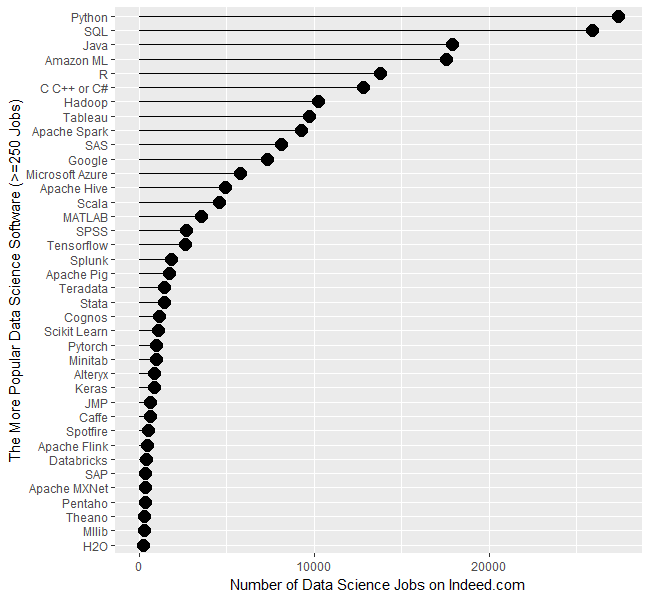
Now, what interests us most today, is that Mr. Muenchen compiles an annual ranking of the most popular software and languages used in data sciences, based on keywords taken from job postings published on job search site Indeed.com. The latest results of his ranking, which covers the period between February 2017 and May 2019, however different from the results of the KDnuggets.com survey,
One cannot disagree with Mr. Rakotomalala that in the current context, which could be described as the “Big Data era” (Big Data is commonly referred to as a large volume of data which is varied, accumulated at high speed and which must be analyzed in real time), that R and Python really stand out and fully justify the investment that could be dedicated to them within the training courses.
The adoption of R and Python in data science degrees seems obvious. However, it is weaker for R. So let’s analyze its strengths and weaknesses.
R’s strengths
its open-source license complies with two fundamental characteristics which are :
access to the source code, guaranteeing us some control over the computing algorithms and operations actually performed in the background;
they can be used and exploited for free, whatever the context of use.
The source code (R, C, FORTRAN) is free of access and consultation, only the modification is subject to validation by the moderating body, the R Foundation.
What’s more, the source code is of quality, meaning that it is copiously accompanied by comments and respects certain conventions. In particular, the implemented instructions are accompanied by references to published scientific articles, offering the reader the possibility to compare the formulas in the research papers and the corresponding instructions implemented in the source code.
notorious computational engine (LAPACK) and used in other software on the market (Maple, MATLAB, Stata),
a whole lot of extensions — third-party packages,
a language that is easy to understand and learn; moreover, being close enough in its syntax to Python, R can both make learning Python easier for those who have never done it, and, conversely, be assimilated faster by someone who has prior working experience with Python.
“The first year I introduced Python for the bachelor’s degree [in the fall of 2015], the students then in Master’s degree came to me and said that they too would like to learn it… because they felt that everyone was talking about Python more and more, both on the Internet and in the press. These were people who had never worked with Python in their lives [but who already knew R]. So I offered them an improvised 6-hour training course on the last Friday before the Christmas break… For one, everyone showed up! The training session went very well, everyone was happy. I then asked everyone to do a project in Python —and not the easiest one— and they did very well. It shows that the gap between Python and R is not huge and that the students are able, after a training of only 6 hours, to make interesting projects —and with a minimal pedagogical cost: the programming framework is the same, the syntax is a bit different, the package names are different too, but the rest is the same.” (01:11:27)
a wealth of online documentation sources, official and third-party;
user-friendly, forum-like, bug tracker;
continuous improvement of the ecosystem: testing, identification and correction of bugs; performance improvement; addition of new features; correction of “cosmetic” aspects such as the quality of graphics rendering.
R’s weaknesses
(which are in fact never other than those of any software, open-source or commercial)
when an increased interest in a technology at a certain point in time is a fad (a famous speaker presented something, his demo was pretty convincing, then media from all over the world picked it up, feeding a months-long buzz);
when there are backwards compatibility problems (such as a R or a Python script that worked well a few years ago but no longer works today → solution: indicate in the script the version of R or Python for which the script was developed at the time);
when graphic libraries produce “exotic” or odd diagrams while one expects something more conventional or neat → solution: search the Internet to see if someone has had this problem before and how it was solved (for example, by using another library or another command), and if not, feel free to ask the question on the Internet yourself.
Problems may exist in connection with third-party packages but these are naturally subject to the laws of natural selection where the survival of a package depends on its real interest for the users: thus, a package rife with bugs and without real interest will not take off and will end up being abandoned even by those who had adopted it; whereas a package that is of interest to the community will see its issues quickly corrected by contributors from all over the world and will eventually outlive its creator. However, this maintenance mode has its limits: while problems deemed to be blocking (slow calculation or calculation inaccuracy) are corrected very quickly by the community of researchers because these aspects are of real interest to them, on the other hand, problems of a “cosmetic” nature (such as the quality of graphics rendering) or lack of user-friendliness take longer to resolve: Thus, the collaboration around a good IDE for R which is RStudio started only in 2010 and the first stable version was released only in 2016, more than twenty years after the creation of R by Ross Ihaka and Robert Gentleman.
no remuneration for package developers;
absence of a sales force as “aggressive” as that of SAS Institute or IBM (vendor of SPSS).
Let’s now assess the strengths and weaknesses of the commercial software SAS:
SAS’s strengths
SAS supporters usually recognize one strength to it —the only one, it seems— which is the reliability of the SAS computational engine, allegedly producing consistent resultats regardless of the processor architecture. This seems to be a self-proclaimed strength, however, because I haven’t found any documented evidence of exceptional and unparalleled performance or a written guarantee of the reliability of their computational engine —and Bob Muenchen says so, too, on his blog in response to one of his readers.
SAS’s weaknesses
cost prohibitive for smaller organizations;
in some cases inaccessible to individuals;
contracts with complicated and restrictive terms of use, with heavy legal sanctions;
closed source code (therefore unauditable);
a notoriously unpalatable programming language with no logic in its syntax. Unlike the R scripting language whose developers, it seems, kept in mind the idea of grammatical consistency, the SAS scripting language is so ridiculously inconsistent one may wonder whether it might have been developed by several researchers who perhaps never talked to each other and never got acquainted with other SAS commands than those they developed for themselves. The fact that SAS’ defects are not remedied over time says much about SAS Institute’s unwillingness to question itself and move toward more modern semantic paradigms, and its indifference towards the poor user experience with its software.
But let’s go back to the “in-depth reflection on the key characteristics that teaching software should have”.
Apart from the “golden rule”, any other recommendations?
Software should be able to store and preserve the analysis steps already completed so that the user does not have to repeat them each time the calculation program is opened.
We’re talking about a feature that allows the commands to be saved in a script file, which is well known and appreciated.
The way computing results are rendered to user who ordered them must be as clean and precise as the instructions he or she sent.
I’ll get to that point right below.
Conveying instructions to the computer (i.e. programming) must be done by means of verbal language (i.e. lines of code) and not by diagrams, drawings, or drag-and-drop or click-button behaviours.
The so-called simple interfaces, allowing programming by moving objects around on the screen, were popular at the dawn of the personal computer era in the 1990s, when the general public was barely getting acquainted with IT. Today, at the dawn of 2020s, this kind of approach, although extremely widespread, may only be good for teaching programming to young children. So, Tableau, if you can hear us…
When several existing tools are available to solve a given problem, they should all be taught and students should be allowed to choose which one they prefer.
“In my econometrics course, I make my students do six 1-hour 45-minute practical sessions. In three of them I have them practice Excel —obviously because students will do their internships with Excel. Then another practical session in R, and a tutorial: the step-by-step guide I wrote for the session, with all major steps outlined; and in only 1 hour and 45 minutes, the students can learn R programming skills, so I don’t see what the difficulty is. Then I make them do a fifth session in Python in the same way. Finally, the last one, the sixth, is the test —and they are allowed to choose their tool. Every year, about half choose Excel, about a quarter choose R and a quarter choose Python.” (55:22)
The teaching of programming languages must be given as a dedicated subject, outside the subjects teaching theoretical methods.
The training must be optimally constructed in such a way that its essential parts —the theoretical course and the practical application on machines— do not cannibalize with one another but each have the training duration they deserve.
The software used in TD must be available for students to practice at home.
The barriers here are the cost of the software license and the compatibility of the software with the operating system installed on the student’s computer. Because even if the university pays the license fee to all its students, the installation can still be problematic.
First, installing SAS also requires installing virtualization software and setting up a virtual machine… a real pain for users who don’t like to solve technical problems but just want a tool that does the job out of the box.
Secondly, since SAS only exists for Windows, a student like me, who chose to run my computer with Linux, cannot install it, unless I use the SAS Web client (which I used when I had to) or use WINE or an emulator (brave people tried it, in 2009 and 2010, with more or less success). The most reasonable alternative appears to be installing R instead of SAS: R is a software that exists for Windows, Linux and MacOS (which comes from the Linux family) and can be installed without driving the user crazy.
The software or a programming language must be able to evolve organically to remain relevant, with new features popping up and evolving spontaneously under conditions that make possible for these to be peer-reviewed.
For example, for such a trendy issue as the “Big Data” —huge amounts of varied data accumulating at high speed in real time— to be addressed, modern statistical software must be able to do things it didn’t need to know how to do in the past, like supporting
concurrency by capitalizing on the number of processor cores;
“Thanks to the dynamism of R and the community [of users] that drives R forward, we have features that are really, really interesting,” says Ricco Rakotomalala (01:05:14).
The barriers here are
compatibility: when the development of new features can only be done on machines of a certain type or using a certain type of software;
cost: when development of new features requires relatively (or extremely) expensive software;
when the source code is the intellectual property of a person or a company, thus making access to it impossible, let alone editing thereof;
The best solution seems, once again, to opt for open-source software.
Curriculum needs to be adapted to the students’ skills.
“In L3 DSI [senior year of Bachelor’s degree in data sciences and computer science], I have a programming course that is complemented with an algorithmic course. We made the choice to work under Delphi. What’s very interesting is that twenty years ago Delphi was taught in M2 [senior year of Master’s degree]; we took it down to M1 and then to bachelor’s level. My data mining course, which I was doing in M2, now I’m doing it in M1. So there’s a real progression in students’ skills.” (01:06:18)
Curriculum needs to keep up with its time.
“What’s great about tcomputer science is that you can’t fall asleep: you have to watch what’s going on all the time because it’s changing so much. At one point, we wondered if it was still relevant to work with Delphi. Because if you go to the Apec [Apec.fr is one of France’s major job offers database for skilled white-collar talents] and run a search on the keyword “delphi”, you’ll still find a few job offers, we agree on that [the search returned 71 job offers from all over France, in contrast to the Python keyword, which returned 1,819 results]. Delphi was a very popular IDE fifteen years ago, but hey: it was fifteen years ago.” (01:07:04)
Tap into multiple sources for insights
Be it about including a new course on an interesting but still little-known piece of software or programming language; or about taking out of the curriculum a software tool or a programming language that has had its day: how do we know if the time is right? The best strategy appears to be tapping into multiple sources for insights. In this case, Mr. Rakotomalala explains that what led him to replace Delphi with Python in 2014 for the 2015 school year, was a combination of early warning signs:
Python was slowly getting to the top of the most popular languages on KDnuggets;
trend analysis results of job postings picked up on Apec.fr and elsewhere on the Internet.
Mr. Rakotomalala recounts how in 2017 a group of students from his master’s degree/programme did a text mining project on several hundred job offers from companies based all over France, written in French and found on the Web (LinkedIn, Apec.fr, etc.), which the students had first to read and tag by hand… The goal was to identify the most correlated keywords for job offers in “classic” statistics as opposed to those in data sciences. The results show that Python enjoys a rather singular place among them: while job offers for positions in “classic” statistics feature most often keywords like “statistics”, followed by (in no particular order here) “SAS”, “SAP”, “Excel” and names of databases, the picture however is different when it comes to job offers in data sciences: the most frequent keyword is still “statistics”, followed by “Python”, “R”, “machine learning”, “algorithm”, “SQL” and “English”.
Therefore, it is not surprising that in the decision tree of the predictive model automatically elaborated on the basis of these job offers, the first criteria allowing to sort out the job offers that are really data sciences related — is the word “Python”. Way more than a fad, skills in Python are truly part of companies’ needs.
Let’s have some fun and try the same experiment
I made a similar experiment out of curiosity in order to know how often the names of different software or programming languages taught today in several post-graduate degrees in data sciences and BI appear in recent job offers. So I launched a few search requests:
in late December 2019;
on two job search sites, Apec.fr and LinkedIn.com, that I chose arbitrarily but whose reputation and diversity of offers should arguably ensure representative and coherent results;
in three geographical areas: all of France, the Île-de-France region and finally the two departments of the former Nord—Pas-de-Calais region where two Master’s degrees offer training in BI, data sciences and machine learning: the SIAD master’s degree of the faculty of economic and social sciences, and the DS master’s degree of the faculty of science and technology;
by accompanying the keywords of interest with one of the two subsidiary keywords —“statistics” or “data”,— which are supposed to both refine the search and, being sufficiently generic, not to bias the results;
without specifying any other criteria.
And this is what we observed:
(It should be noted that the requests concerning R, which were initially intended to be included in this sample, had to be completely excluded from it because their results were systematically “polluted” by unrelated offers containing the acronym “R&D”. The work would have required further text-mining research, whose hourly volume would have been disproportional to the interest and the very raison d’être of this essay).
We can make several observations regarding the results:
LinkedIn systematically returned considerably more results than Apec.fr, the only exception being the “python statistics” request for the Nord and Pas-de-Calais departments;
with a few exceptions, searches containing the subsidiary keyword “data” tend to return more results than the searches containing the subsidiary keyword “statistic”, and this for both search engines;
a low number of results for two Microsoft technologies: VBA (Visual Basic Application) and Access:
VBA is the development environment created by Microsoft for the Visual Basic scripting language, also created by Microsoft, to program “macros” (automated procedures) for the Office package (another Microsoft creation): Word, Excel, PowerPoint and Access.
Access is the DBMS of Microsoft’s Office package, which was popular in the 1990s and 2000s for lack of other alternatives at the time, but from which market has started to lose interest since the beginning of the “Web 2.0” era and the massive arrival of all the various Web platforms allowing to store and edit data online, directly in the browser.
These are two examples of software whose teaching goes against the “golden rule” and which should in principle be removed from a Data Science curriculum. Especially given that the number of teaching hours in a master’s degree is limited and it is often difficult to add hours of teaching without having to remove others.
A conclusion of sorts
Being used in companies is, for a given IT tool, undoubtedly one of the determining factors in the choice of its integration in BI and data sciences oriented degree; it is indeed the “golden rule”, they say, among the choice criteria: the more widespread a software is, the more it must be adopted.
But is this always true?
How IBM has gained market share in Eastern Europe
Somebody told me how IBM manages to gain market shares in Eastern Europe which it then holds forever, as in a forced, life-long marriage. In those countries, major companies in the banking, finance and transport sectors (typical IBM clients in France) are not so big and usually do not have the means to afford the unbearable cost of IBM licenses and operating expenses. However, since large companies in neighboring countries are already customers of IBM and benefit from transaction facilities and other benefits, new customers agree more easily, which allows IBM to convert more and more companies and gain more and more market shares. These benefits, which are basically unnecessary and completely artificial, end up appearing essential. Just as ill-intentioned cigarette manufacturers used to make people believe, before cigarette advertising was completely banned in France, that smoking made people more popular and made their lives happier; and smokers, once addicted, no longer knew why they kept smoking every day, whereas at first, they only used to smoke socially.
Once the need is created, IBM sends in to these countries skillful salespeople who pull out all the stops and negotiate with large companies and public services using their usual rhetorics (“IBM is the gold standard of security and reliability”, “IBM is big and serious, and so are its customers”, “IBM is American”…). For the starters, they offer companies a trial period and a discount. It’s not yet a marriage but it is, so to speak, pretty much an engagement.
IBM software is designed to work best with IBM hardware, and companies that have started integrating their software are offered a trial of IBM hardware, again at a discount and even with payment facilities like a bank loan. Of course, the products they can afford themselves with their modest budget are not of the latest generation or are even completely obsolete. “But hey, this is still IBM stuff, we’ll be fine!,” think senior executives of the newly acquired IBM customers, without wondering about woes that staff members —who will have to work directly with that hardware and software— will have to endure every weekday.
Once the Mainframe servers are installed, the forced marriage is pronounced. Very quickly, the bill rises and, although the company will never stop regretting it afterwards, divorcing IBM would be even more expensive than continuing to incur huge operating and licensing costs. As a result, the company will not be able to afford an upgrade for years to come, condemning its staff to having to work with obsolete hardware and software. Furthermore, any possibility of compatibility with other software or hardware components will be eliminated: to be compatible with IBM products, a third-party hardware or software product must be IBM certified; and for this you must either pay IBM or be part of IBM. Needless to say that such practices make many people unhappy.
That’s the way IBM makes money, but chances are that this could just as well be the case for Microsoft: both
subject their customers to “shotgun wedding” contracts,
do rarely comply to world’s standards designed to allow for better compatibility and interoperability; still, those two always seek to reinvent their own wheel,
kill the tech industry with anti-competitive and unconstructive practices,
make big money without really contributing to innovation, but constantly arguing they are champions of progress.
While IBM and Microsoft software are of poor quality most of the time, it is still ubiquitous and makes itself count. Also, Microsoft has dangerously infected absolutely all nooks and crannies of France’s education and research ecosystem — some favours it does not deserve. How is that possible?
But you only have to listen to common sense to realize that their notoriety and market share is even more of a fake than Paris Hilton’s nanotechnological water (which at least is funny).
Wait… One cannot fool all the people all the time, right?
In our world, there are probably more believers or followers of a religion than there are atheists. Some countries have an “official” religion, while others, such as France, are lay. Which way is the most constructive? What does common sense say?
If we sought to measure how many people in the world have used Windows at least once during a given month, should we include people like me who, despite having stopped using Windows at home in favour of Ubuntu Linux since 2013, have regularly no other choice than to use Windows at work, in libraries, during practical session at university or when a friend asks me to fix a technical problem on his or her Windows PC.
Even though the number of people who have used Windows at least once in a month may represent, say, more than 90% of the world’s population, is that an indicator of its popularity? If we kept only those people who felt pleasure in using Windows or found it efficient, the rate thereby measured would quickly and brutally whittled away.
And yet, Windows is everywhere, like a fair share of other Microsoft software.
But if that defies all logic, how can that be?
Unfortunately, all too often, counter-intuitive choices in the matter of software used in companies are due to the fact that the decision-makers are not those for whom using that software is part of their job. In France, this issue can be met in most major State-run agencies and private companies —public services, schools and universities, large banking and insurance institutions. Companies that choose commercial software —which is expensive and often of poor quality, user-unfriendly and prone to compatibility issues,— shoot themselves at least three bullets in the foot:
they make their staff use poor quality software that creates problems and hampers their daily workflows;
spending large sums of money to pay for commercial software licences, their senior executives have to operate cost cuts elsewhere, often in hardware equipment, thus making their staff use old computers every weekday;
buying software or hardware from a predatory vendor such as Microsoft or IBM, their customers —among which the French State-run bodies— favour the status quo in the IT economy and feed a dangerous and anti-competitive oligopoly.
Bend that “golden rule”: Software and programming languages should be taught proportionally to their popularity among people who use them.
It is not a problem, per se, that commercial software such as SAS or Excel is taught in BI degrees: these two are indeed very widespread in companies, and students eager to be hired in IT contractors force providers should adopt them, just as university degrees should teach them to see as many of their young graduates recruited as quickly as possible. However, teaching major software must also be fair and proportional not only to their market share but also to their popularity among people who use them on a regular basis. And open source software should not be ignored.
Arguably, there is a problem when commercial software, which is widespread but poor in many ways, enjoys being software of choice in a training course, while, on the other hand, worldwide known and recognized open source software that has all the pros of its commercial rival without any of its flaws,— is no software of choice; or, at best, has to be taught as part of another course, —and even then, only by the personal will of a teacher who is more open than the others. Even more regrettable is the fact that teaching of outdated technologies such as Microsoft Access or VBA continues to be part of some curricula, thereby violating the “golden rule” and being completely irrational. It seems in the end that this golden rule is not a true golden one, and that it can be bent when needed.
Therefore, university professors had better regain their courage and their role as enlightened guides and creators of knowledge and, armed with the findings of their research, show the way to senior executives, whose job is not about thinking. All that is needed to capture their attention is to show them there is a good opportunity to cut costs.
It is clear that one cannot get large French companies and State-run bodies —many of which are today fully equipped with Microsoft software (Windows, Azure, Office, Outlook, Internet Explorer and so on) and IBM servers— to give it up overnight for open-source software; just as one cannot get a person fully equipped with Apple to adopt an Android-run smartphone. But that’s not a reason not to talk to them.
What, you think they won’t listen?
IT behemoths keep generating their needless, fake buzz and don’t care if anyone reads, watches or listens. As a result, their stuff is the one people hear the most.
Je ne sais pas encore ce que ça vaut, mais dans une vidéo YouTube en russe, dont je vais résumer le début, un type explique qu’il a vu dans une émission russe qu’il est possible d’obtenir un whisky vieilli de 4 ans en seulement 4 jours en procédant par une technique de chauffe, apparemment inventée et pratiquée par les Américains.
La technique repose sur l’idée qu’un whisky devient meilleur s’il est porté à 65° C, et consiste à chauffer les fûts en bois de chêne ou, dans l’exemple de la vidéo, la bonbonne maison remplie de moût fermenté (appelé en anglais « wash » et en russe « samogon ») et de dés de bois de chêne, et ce en alternant les phases contrastées de chauffe et de refroidissement à raison de 24 heures par phase. Autrement dit, d’abord porter le contenu à 65° C pendant 24 heures, ensuite refroidir la bonbonne pendant les 24 heures suivantes (dehors, dans la neige, oui oui, la totale), ensuite chauffer à nouveau pendant 24 heures et enfin refroidir durant les 24 dernières heures.
Dans l’enseignement de l’informatique décisionnelle et des data sciences, l’enjeu principal, la « règle d’or » pour les formations, est incontestablement de former des profils professionnels intéressants sur le marché de l’emploi. Le choix d’outils informatiques sur lesquels se basent les formations est l’un des facteurs déterminants dans un contexte d’une certaine abondance : outils exotiques bénéficiant d’un effet de mode dont on ne sait s’il faut se méfier ; outils anciens —peut-être trop anciens pour certains— mais éprouvés par le temps ; outils commerciaux, à la fois onéreux et d’une qualité ou d’une ergonomie laissant souvent à désirer, mais qui sont cependant largement adoptés voire omniprésents et qui, de ce fait, s’imposent contre toute logique ; outils libres, dont certains ont beaucoup pour plaire, mais qui restent pourtant marginaux sur le marché. Dans cet embarras de choix et devant, en plus, se plier aux diverses contraintes budgétaires et légales, les universitaires sont confrontés au dilemme de concilier cette première vocation, qui est de former des jeunes diplômés en adéquation avec la donne du marché, avec l’autre vocation des universités en tant que pôles d’excellences et temples du savoir, qui est de diffuser le savoir, les bonnes pratiques et les meilleures méthodes issues des dernières recherches.
Dans cet essai, nous allons d’abord présenter, à travers deux sources, ce qu’est la réalité du marché en termes de préférence pour les logiciels et langages utilisés en informatique décisionnelle et en data sciences. Et de voir ensuite comment la sacro-sainte « règle d’or » est tantôt brandie —lorsqu’il s’agit de justifier la signature d’un « partenariat » favoritiste et anticoncurrentiel passé à la vue de tous entre l’État et l’un des éditeurs-prédateurs du marché du logiciel informatique commercial—, tantôt violée (contre toute logique). Mais à qui profite le crime ? Semble-t-il, toujours aux mêmes.
* *
*
Connaître les préférences du marché
Ricco Rakotomalala est plutôt bien connu sur le Web : enseignant-chercheur et responsable, depuis 2013, du Master SISE à l’Université Lyon 2, —un master qui a une chaîne YouTube créée en 2015, « Lyon Data Science », plutôt intéressante—, créateur de logiciels de data mining libres et gratuits à vocation pédagogique (SIPINA, TANAGRA) et l’auteur de nombreux tutoriels et d’ouvrages en accès libre.
Dans une vidéo publiée en janvier 2018 et intitulée « Place de R et Python dans les formations en Data Science », M. Rakotomalala livre une conférence de plus d’une heure et demi née d’« une réflexion approfondie sur les caractéristiques clés que doivent présenter les logiciels pour l’enseignement ». Desquelles caractéristiques la première est la « règle d’or » qu’on a déjà présentée plus haut, dans l’introduction :
Les logiciels enseignés en formations universitaires doivent être ceux réellement utilisés dans les entreprises ou, a minima, y ressembler.
La logique derrière cette règle est claire : les jeunes diplômés doivent être formés aux outils utilisés par les entreprises susceptibles de les embaucher. Dès lors, comment connaître les préférences du marché ?
KDnuggets.com
Pour une formation modeste, à portée départementale ou régionale, il suffit que ses responsables se renseignent auprès des entreprises locales ; et tant pis si la formation finira vite par s’enfermer dans des « partenariats » totalement abusifs avec Microsoft, SAS et IBM : lorsqu’il faut ménager la chèvre et le chou et devoir régulièrement justifier son budget auprès de l’État par des taux d’embauche décents, tous les moyens sont bons.
Une autre idée peut être de consulter les résultats d’un sondage spécialisé, une source d’information complémentaire et édifiante, surtout si le sondage porte sur d’autres pays « informatisés » du monde. L’un des sondages portant sur les logiciels et langages d’analyse statistique est conduit chaque année au mois de mai depuis voilà vingt ans par le site KDnuggets.com. Dans sa vidéo de janvier 2018, M. Rakotomalala compare les résultats de 2017 (ce sera 2019 pour nous) à ceux de 2005 et apporte quelques commentaires (écouter ses explications dans la vidéo de son intervention à partir de 33:27) :
R, bien que n’étant pas le premier du classement, est extrêmement populaire, y compris de l’expérience personnelle de M. Rakotomalala : les supports de cours et exercices de R qu’il met à disposition sur son site web personnel en constituent les pages les plus visitées. R a connu une montée impressionnante dans ce classement en passant de tout en bas à la deuxième place (du classement de 2017). L’intervenant trouve le parcours de R remarquable, ce qui le distingue d’autres outils libres d’analyse statistique ayant eu la même genèse mais restés à la marge : tel a été notamment le cas des logiciels libres dont M. Rakotomalala a été le créateur pour l’un (TANGRA) et le contributeur pour l’autre (SIPINA). « R est un outil libre à la base, un outil universitaire… En fait il y a un article, sur NYTimes [de 2009], qui explique l’origine de R, avec Ross Ihaka et [Robert] Gentleman, où ils expliquent le cheminement et tout ça… c’est un travail universitaire. J’aurais pu faire la même chose. L’élément clé c’est que cet outil-là maintenant est rentré dans les entreprises. » (48:23)
L’évolution du langage Python a été encore plus impressionnante : plus populaire que R, plus populaire que touten matière de data sciences, Python domine ce classement depuis quelques années, tandis qu’en 2005 ce langage de script n’en faisait même pas partie.
Remarquons également qu’Excel était un logiciel suffisant pour les statisticiens dans les années 1990 et 2000 et qu’il restait incontournable en 2005 (3e place du classement). Aujourd’hui par contre, bien que toujours incontournable (4e place), ce logiciel n’est plus suffisant : les données sont devenue trop volumineuses, les systèmes : interconnectés et orientés Web, et les procédures y sont, pour beaucoup, automatisées. L’outil de prédilection en études statistiques classiques, Excel n’a aucune utilité en data sciences ou machine learning (apprentissage non supervisé).
r4stats.com
Pour ne pas se limiter à l’unique argument d’autorité que sont les résultats du sondage du site KDnuggets.com, en voici un autre : celui du blog r4stats.com : un site personnel (et vraisemblablement indépendant) qui poursuit deux objectifs :
analyser ce qui se passe dans le domaine des ou de la data science,
aider le public à se familiariser avec R dans un monde aujourd’hui encore dominé par les « trois géants » du logiciel statistique qui sont les logiciels propriétaires et payants SAS de SAS Institute, SPSS d’IBM et Stata de StataCorp.
L’auteur de ce blog créé en 2012 est Bob Muenchen, un universitaire américain qui
gère les contrats passés avec les éditeurs de logiciels de calcul scientifique pour le compte de l’université de Tennessee (information indiquée en réponse à l’un des lecteurs du blog) ;
connaît aussi bien R que les logiciels commerciaux susmentionnés puisqu’il est l’auteur d’ouvrages R for SAS and SPSS Users et R for Stata Users ;
Enfin, ce qui nous intéresse le plus aujourd’hui, M. Muenchen dresse chaque année un classement des logiciels et langages les plus utilisés en data sciences, élaboré sur la base de mots-clés extraits des offres d’emploi publiés sur le site Indeed.com. Les derniers résultats de son classement, établi sur la période entre février 2017 et mai 2019, bien que sont différents des résultats du sondage de KDnuggets.com,
donnent tout de même assurément la première place à Python ;
montrent que R est presque deux fois plus répandu que SAS ;
On ne peut pas ne pas être d’accord avec M. Rakotomalala sur le fait que dans le contexte actuel que l’on pourrait qualifier de « l’ère du Big Data » (on appelle communément Big Data un grand volume de données variées, accumulées à grande vitesse et qu’il faut analyser en temps réel), que R et Python se démarquent réellement et justifient pleinement l’investissement que l’on pourrait leur consacrer au sein des formations.
L’adoption de R et Python dans les formations en data science semble évidente. Et pourtant, elle est moindre pour R. Analysons donc ses forces et ses faiblesses.
Les forces de R
sa licence libre respecte deux caractéristiques fondamentales de :
accès au code source, nous garantissant un certain contrôle sur les calculs et opérations réellement effectuées ;
ils sont accessibles et exploitables gratuitement, quels que soient les contextes d’utilisation.
Le code source (R, C, FORTRAN) est libre d’accès et de consultation, seule la modification est soumise à la validation par l’organisme modérateur, la fondation R Foundation.
Qui plus est, le code source est de qualité, c’est-à-dire qu’il est copieusement accompagné de commentaires et respecte certaines conventions. Les instructions implémentées sont notamment accompagnées de renvois aux articles scientifiques publiés, offrant au lecteur la possibilité de comparer les formules dans les publications et les instructions correspondantes implémentées dans le code source.
moteur de calcul reconnu (LAPACK) et utilisé dans d’autres logiciels du marché (Maple, MATLAB, Stata)
nombreuses extensions
un langage facile à comprendre et à apprendre ; de plus, assez proche dans sa syntaxe de Python, R peut aussi bien faciliter l’apprentissage de Python à celles et ceux qui n’en ont jamais fait, comme il peut lui, réciproquement, être assimilé plus vite par quelqu’un qui a déjà fait du Python.
« La première année où j’ai introduit Python en licence [à la rentrée 2015], des étudiants en M1 et en M2 sont venus me voir pour dire qu’ils aimeraient eux aussi en faire… parce qu’ils avaient l’impression que tout le monde parlait de Python de plus en plus, sur Internet et dans la presse. C’était des gens qui n’avaient jamais fait de Python de leur vie [mais qui avaient déjà fait pas mal de R]. Je leur ai proposé alors une formation improvisée de 6 h le dernier vendredi avant les vacances de Noël… Déjà, tout le monde est venu ! La formation s’est très bien passée, tout le monde était content. J’ai alors demandé à chacun de faire un projet en Python —et pas des plus simples— et ils se sont très bien débrouillés. Ça montre que le gap entre Python et R n’est pas énorme et que les étudiants sont capables, après une formation de seulement 6 h, de faire des projets intéressants —et ce avec un coût pédagogique minime : la trame de programmation est la même, la syntaxe diffère un peu, les noms des packages aussi, mais le reste est pareil. » (01:11:27)
« Dans la pratique, un data scientist doit maîtriser aussi bien R que Python et son choix dépendra du contexte, des objectifs de l’étude, des packages à sa disposition et de leur qualité. »
profusion de sources de documentation en ligne, officielles et tierces
facilité de remonter des incidents d’utilisation aux développeurs, ou de dialoguer si besoin
amélioration continue de l’écosystème : tests, identification et correction de bugs ; amélioration des performances ; ajout de nouvelles fonctionnalités ; correction d’aspects « cosmétiques » comme la qualité des rendus graphiques.
Les Faiblesses de R
(qui ne sont en réalité jamais autres que celles de n’importe quel outil informatique, libre ou commercial)
lorsqu’un intérêt accru pour une technologie à l’instant t est un effet de mode (un intervenant célèbre a présenté quelque chose, sa « démo » a été plutôt convaincante, ensuite toute la presse du monde l’a repris et voilà des mois que le monde entier continue de parler de ça)
lorsqu’il y a des problèmes de rétrocompatibilité (tel script Python qui marchait bien il y a quelques années mais qui ne marche plus aujourd’hui) → solution : indiquer bien dans le script la version de Python pour laquelle le script a été développé à l’époque
lorsque les bibliothèques de traçage de diagrammes produisent des diagrammes « exotiques » ou bizarres alors qu’on s’attend à quelque chose de plus conforme ou plus soigné → solution : chercher sur Internet si quelqu’un n’aurait pas déjà eu ce problème et comment il a été résolu (par exemple, en utilisant une autre bibliothèque ou une autre commande), sinon ne pas hésiter à poser la question sur Internet soi-même.
des problèmes peuvent exister en lien avec des packages tiers mais ceux-ci subissent naturellement les lois de la sélection naturelle où la survie d’un package dépend de son intérêt réel pour les usagers : ainsi, un package avec des défauts et sans intérêt réel ne trouvera pas de preneur et finira par être abandonné même par ceux qui l’avaient adopté, alors qu’un package qui présente un intérêt pour la communauté verra ses défauts rapidement corrigés par des contributeurs du monde entier et finira par dépasser son créateur. Ce mode de maintenance a néanmoins ses limites : alors que des problèmes jugés bloquants (de lenteur de calcul ou d’imprécision de calcul) sont corrigés très rapidement par la communauté car ces aspects-là présentent un intérêt réel pour les chercheurs, en revanche des problèmes d’ordre « cosmétique » (comme la qualité des rendus graphiques) ou de facilité d’utilisation se font attendre plus longtemps : ainsi, la collaboration autour d’un bon IDE pour R qu’est RStudio n’a commencé qu’en 2010 et la première version stable en est parue seulement en 2016, soit plus de vingt ans après la création de R par Ross Ihaka et Robert Gentleman.
absence de rémunération pour les développeurs de packages
absence d’une force de vente aussi « agressive » que celle de SAS Institute ou d’IBM (éditeur de SPSS).
Évaluons maintenant les forces et faiblesses du logiciel commercial de statistique SAS :
Les forces du logiciel commercial SAS
Pour ce qui est de SAS, ses partisans lui reconnaissent un atout —le seul, semble-t-il— c’est la fiabilité du moteur de calcul de SAS, apparemment quelle que soit l’architecture du processeur. Un atout qui semble toutefois être autoproclamé car je n’ai pas trouvé ni les preuves documentées d’une performance exceptionnelle et inégalée, ni une garantie écrite de fiabilité de leur moteur de calcul — Et Bob Muenchen l’affirme, lui aussi, sur son blog en réponse à l’un de ses lecteurs.
Les Faiblesses du logiciel commercial SAS
un coût prohibitif pour les TPE ou les PME
dans certains cas, impossible d’utiliser pour les particuliers
contrats compliqués, des règles d’utilisation restreintes, sanctions juridiques sévères
code source fermé (donc invérifiable)
un langage de programmation notoirement indigeste et n’ayant aucune logique dans sa syntaxe. (Contrairement au langage de R —dont les concepteurs ont vraisemblablement gardé à l’esprit l’idée de rendre la syntaxe de celui-ci logique et facilement assimilable—, le langage de SAS est à tel point dépourvu de toute logique qu’on se demande si les chercheurs qui l’ont mis au point se sont jamais parlés ou s’ils ont jamais pris le soin de découvrir les commandes autres que celles qu’ils ont développées eux-mêmes…)
Le fait que les défauts de SAS ne sont pas palliés avec le temps en dit long sur l’indisposition de SAS Institute, son éditeur, à se remettre en question et témoigne de son indifférence vis-à-vis de la mauvaise expérience utilisateur engendrée par son outil.
Mais revenons à la « réflexion approfondie sur les caractéristiques clés que doivent présenter les logiciels pour l’enseignement ».
Hormis la « règle d’or », quelles recommandations ?
Il faut un outil qui conserve les étapes d’analyse déjà accomplies afin d’éviter à l’usager de les refaire chaque fois à l’ouverture du programme de calcul.
Il s’agit de la fonctionnalité permettant la sauvegarde des commandes dans un fichier de script. On la connaît bien et c’est fort pratique.
Les instructions transmises au logiciel par l’usager étant précises, il faut que les manières de les sauvegarder par le logiciel et de les visualiser ensuite devant l’utilisateur soient tout aussi précises et non approximatives.
Je vais y venir juste ci-dessous.
La transmission d’instructions à la machine (la programmation) doit se faire par le truchement d’un langage verbal (des lignes de code) et non par la représentation avec un schéma, un dessin, du glisser-déposer ou du clic-bouton.
Les interfaces soi-disant faciles, permettant la programmation en déplaçant des objets sur l’écran, c’était bien à l’aube de l’ère des ordinateurs personnels, dans les années 1990, lorsque le grand public découvrait à peine l’informatique. Aujourd’hui, à l’aube des années 2020, ce genre d’approche, pourtant extrêmement répandu, est tout juste bon pour apprendre à programmer aux enfants en bas âge. Alors, Tableau, si tu m’entends…
Lorsque plusieurs outils existants permettent de résoudre un problème donné, il faut les enseigner tous et laisser aux étudiants de choisir celui qu’ils ou elles préfèrent.
« Dans mon cours d’économétrie, je fais faire à mes étudiants six TP de 1 h 45. Trois en sont sous Excel —parce qu’ils vont faire leur stage sous Excel, clairement. Ensuite un TP sous R, et ils ont le tutoriel à côté : c’est ma fiche de TP, avec les bons repères ; et en 1 h 45 seulement, les étudiants peuvent développer une compétence R, je ne vois pas où est la difficulté. Ensuite, je leur fais faire un cinquième TP sous Python et c’est pareil. Enfin, le dernier, le TP n° 6, c’est l’évaluation —et ils ont le choix de l’outil. Tous les ans, à peu près la moitié fait le choix d’Excel, un quart choisit R et un quart Python. » (55:22)
Il faut que les enseignements de langages de programmation soit dispensés à part entière et en dehors des matières enseignant les méthodes théoriques.
La formation doit être construite de manière optimale de telle sorte que ses parties essentielles —le cours théorique et l’application pratique sur machines— ne phagocytent pas les unes les autres mais disposent chacune d’une durée de formation qu’elles méritent.
Il faut que le logiciel utilisé en TD soit accessible par les étudiants chez eux.
Les barrières, ici, sont le coût de la licence du logiciel et la compatibilité de celui-ci avec le système d’exploitation installé sur l’ordinateur de l’étudiant. Car même si la fac paye la licence à tous ses étudiants, l’installation peut néanmoins être problématique.
Premièrement, l’installation de SAS nécessite d’installer, en plus, des logiciels de virtualisation et de créer une machine virtuelle… une vraie plaie pour les utilisateurs qui n’ont pas vocation à aimer résoudre des problèmes techniques.
Deuxièmement, SAS n’existant qu’en version Windows, un étudiant comme moi, qui ai choisi d’équiper ma machine de Linux, ne peut pas l’installer, à moins d’utiliser le client Web de SAS (que j’ai utilisé lorsque j’étais obligé) ou d’utiliser WINE ou un émulateur (des braves gens l’ont essayé, en 2009 et en 2010, avec plus ou moins de succès). L’alternative la plus raisonnable semble d’installer R à la place de SAS : R est un logiciel qui existe pour Windows comme pour Linux comme pour MacOS (qui est de la famille Linux à la base) et qui s’installe sans rendre l’utilisateur fou de rage au point de s’arracher les cheveux sur la tête.
Il faut que le logiciel ou le langage puisse se développer organiquement pour rester d’actualité, que de nouvelles fonctionnalités s’amorcent, se développent de manière spontanée et que la révision par des pairs de la qualité de celles-ci soit facilitée.
À titre d’exemple, une problématique bien d’actualité sont les « Big Data », ces masses de données volumineuses, variées et s’accumulant à grande vitesse en temps réel. Pour pouvoir s’attaquer à celles-ci, il faut qu’un logiciel de calcul statistique puisse faire aujourd’hui des choses qu’il n’avait pas besoin de savoir faire auparavant :
de la programmation parallèle (en anglais concurrency) en capitalisant sur le nombre de noyaux du processeur ;
« Grâce au dynamisme de R et de la communauté [de ses utilisateurs] qui fait avancer R, on a des fonctionnalités qui sont réellement très très intéressantes », se félicite Ricco Rakotomalala (01:05:14).
Les barrières, ici, sont
la compatibilité : lorsque le développent de nouvelles fonctionnalités ne puisse se faire que sur des machines d’un certain type ou via un logiciel d’un certain type ;
le coût : lorsque le développent de nouvelles fonctionnalités ne puisse se faire que via un logiciel relativement (ou extrêmement) onéreux ;
le code source étant la propriété intellectuelle d’une personne ou d’une société, y avoir accès est impossible, encore moins pouvoir le modifier.
La meilleure solution semble, là encore, d’opter pour des logiciels libres (open-source).
Faire adapter le programme aux facultés des étudiants.
« En L3 DSI [data science et informatique], j’ai un cours de programmation qui est « marié » avec un cours d’algorithmie. On a fait le choix de travailler sous Delphi. Ce qui est très intéressant, c’est qu’il y a vingt ans Delphi était enseigné en M2 ; on l’a fait descendre en M1 puis en licence. Mon cours de data mining, que je faisais en M2, maintenant je le fais en M1. Il y a donc une vraie progression des compétences des étudiants. » (01:06:18)
Faire adapter le programme à la réalité du monde informatique.
« Ce qui est bien en informatique c’est qu’on ne peut pas s’endormir : il faut qu’on surveille tout le temps ce qui se passe parce que ça évolue beaucoup. À un moment donné, on s’est demandé s’il était encore pertinent de travailler sous Delphi. Parce que si on va sur le site de l’Apec et qu’on lance une recheche sur le mot-clé « delphi », on trouve quand même quelques offres d’emploi, on est d’accord [la recherche retourne 71 offres d’emploi sur toute la France, contrairement au mot clé Python qui retourne 1 819 résultats]. Delphi était un environnement de programmation qui était très en vogue il y a quinze ans, mais justement : c’était il y a quinze ans. » (01:07:04)
Multiplier les sources de veille
Qu’il s’agisse de trancher s’il faut ou non inclure un logiciel ou langage intéressant mais encore peu connu ; ou bien de sortir du cursus un logiciel ou langage qui a fait son temps : comment savoir si le moment en est venu ? La meilleure stratégie semble de multiplier ses sources de veille. En l’occurrence, M. Rakotomalala explique que ce qui l’a poussé à remplacer Delphi par Python en 2014 pour la rentrée 2015 était un concours de signes précurseurs :
on voyait Python arriver petit à petit en tête des langages les plus populaires sur KDnuggets ;
les résultats d’analyse des tendances des offres d’emploi ramassés sur Apec et ailleurs sur Internet.
M. Rakotomalala raconte comment en 2017 un groupe d’étudiants de son master a fait un projet de text mining sur plusieurs centaines d’offres d’emploi trouvés sur LinkedIn, sur Apec.fr, etc., qu’ils ont d’abord lus et étiquetés à la main… Le but était d’essayer de cerner les mots-clés importants qui caractérisent les annonces partout en France. Les résultats montrent que Python y occupe une place assez singulière. Ainsi, alors que dans les annonces pour les postes de chargé d’études statistiques « classiques », les mots-clés qui ressortent le plus souvent sont « statistique », « SAS », « SAP », « Excel » et les bases de données, le paysage est en revanche différent pour ce qui est des data scientists : le mot-clé le plus fréquent est toujours « statistique » mais les autres mots-clés intéressants sont « Python », « R », « machine learning », « algorithme », « SQL » et « anglais ».
De là, il n’est pas étonnant que dans l’arbre de décision du modèle prédictif élaboré automatiquement sur la base de ces offres d’emploi là, c’est la présence du mot-clé « Python » qui apparaît comme le premier critère permettant de faire le tri entre les offres d’emploi qui relèvent véritablement de la data science. Plus qu’un phénomène de mode, les compétences en Python font véritablement partie des besoins des entreprises.
Tentons la même expérience
J’ai fait une expérience similaire par curiosité de découvrir le nombre de fois où les noms des différents logiciels ou langages enseignés aujourd’hui en différentes formations en data sciences et à l’informatique décisionnelle de niveau master, en lançant quelques requêtes de recherche :
en fin décembre 2019 ;
sur deux sites de recherche d’emploi, Apec.fr et LinkedIn.com, que j’ai choisis arbitrairement mais dont la notoriété et la diversité des offres devraient en principe assurer des résultats reflétant suffisamment bien la réalité ;
sur trois zones géographiques : toute la France, la région Île-de-France et enfin les deux départements de l’ex-région Nord—Pas-de-Calais où deux masters offrent une formation en BI, data sciences et machine learning : le master SIAD de la faculté des sciences économiques et sociales, et le master DS de la faculté des sciences et technologies ;
en accompagnant les mots-clés d’intérêt d’un des deux mots-clés subsidiaires, « statistique » ou « data », censés à la fois affiner la recherche et, étant suffisamment génériques, ne pas biaiser les résultats ;
sans préciser d’autre critère.
Et voici ce que nous avons observé :
(À noter que les requêtes concernant R, d’abord envisagées d’être incluses dans cet échantillon, ont finalement dû en être entièrement exclues : en effet, leurs résultats ont été systématiquement « pollués » par des offres sans rapport mais contenant le sigle « R&D ». Le travail aurait exigé une recherche de text-mining plus poussée dont le volume horaire dépasserait l’intérêt et la raison d’être de cet essai.)
Nous pouvons faire plusieurs observations au sujet des résultats :
LinkedIn a systématiquement retourné considérablement plus de résultats qu’Apec.fr, la seule exception étant la requête « statistique python » pour les départements Nord et Pas-de-Calais ;
à quelques exceptions près, les requêtes contenant le mot-clé subsidiaire « data » ont tendance à retourner plus de résultats que les requêtes contenant le mot-clé subsidiaire « statistique », et ce pour les deux moteurs de recherche ;
un nombre faible de résultats pour deux technologies de Microsoft : VBA (Visual Basic Application) et Access :
VBA est l’environnement de développement créé par Microsoft pour le langage de script Visual Basic, également créé par Microsoft, pour programmer des « macros » (procédures automatisées) pour les logiciels du pack Office (une autre création de Microsoft) : Word, Excel, PowerPoint et Access.
Access est le SGBD du pack Office de Microsoft qui a été populaire dans les années 1990 et 2000 faute d’autres alternatives à l’époque, mais dont le marché a commencé à se désintéresser depuis le début de l’ère « Web 2.0 » et l’arrivée massive de toutes les diverses plateformes du Web permettant de stocker et d’éditer des données en ligne, à même dans le navigateur.
Voilà deux exemples de logiciels dont l’enseignement va à l’encontre de la « règle d’or » et qui doivent en principe être retirées d’un cursus de data sciences. D’autant plus que le nombre d’heures d’enseignement en master est limité et qu’il est souvent difficile d’ajouter des heures au contenu pédagogique d’un master sans devoir en supprimer d’autres.
*
* *
En guise de conclusion
Le fait d’être utilisé en entreprises est, pour un outil informatique donné, incontestablement un des facteurs déterminants dans le choix de son intégration dans une formation d’informatique ; c’est bien la « règle d’or », dit-on, parmi les critères de choix : plus un logiciel est répandu, plus il faut l’adopter. Mais est-ce la vérité absolue ?
Comment IBM a grappillé des parts de marché en Europe de l’Est
Quelqu’un m’a raconté comment fait IBM pour gagner irrémédiablement (comme un mariage forcé et à vie) des parts de marché dans les pays de l’Europe de l’Est, là où pourtant les grandes entreprises des secteurs bancaire, financier et des transports (les clients typiques d’IBM en France) ne sont pas si grandes et n’ont, en principe, pas les moyens de payer le coût prohibitif des licences et frais d’exploitation du géant américain. Cependant, lorsque les grandes entreprises dans les pays voisins sont déjà clients d’IBM et bénéficient des facilités de transactions et autres bienfaits, les nouveaux clients consentent plus facilement, ce qui permet à IBM de convertir de plus en plus d’entreprises et grappiller de plus en plus de parts de marché. Ces bienfaits-là, à la base non nécessaires et complètement artificiels, finissent par paraître indispensables. Tout comme les fabricants de cigarettes malintentionnés faisaient croire, avant que la publicité des cigarettes ne soit complètement interdite en France, que fumer rend les gens plus populaires et leur vie plus heureuse, les fumeurs, une fois accoutumés, ne savaient plus pourquoi ils fumaient tous les jours, alors qu’au début ils ne fumaient qu’en soirées.
Le besoin une fois créé, IBM envoie dans ces contrées d’habiles commerciaux qui sortent le grand jeu et négocient avec les grandes entreprises et services publics avec des éléments de langage habituels (« IBM est l’étalon or de la sécurité et de la fiabilité », « IBM est le standard », « IBM c’est du sérieux, ses clients aussi », « IBM est américain »…). Pour commencer, ils offrent aux entreprises une période d’essai assortie d’une réduction. Ce n’est pas encore le mariage mais, pour ainsi dire, les fiançailles.
Les logiciels d’IBM étant conçus pour fonctionner le mieux avec du matériel fait maison, les entreprises ayant entamé l’intégration de leurs logiciels se voient proposer un essai du matériel IBM, là encore assorti d’une réduction et même des facilités de paiement sous forme d’un prêt bancaire. Évidemment, les produits auxquels ils ont droit avec leur portefeuille ne sont pas de la première jeunesse voire sont complètement obsolètes. « Mais bon, c’est du IBM et ça ira très bien quand même ! », se disent les cadres dirigeants des nouveaux clients d’IBM sans se poser la question comment vont devoir galérer au quotidien les membres du personnel qui seront amener à travailler directement avec ce matériel et ces logiciels.
Les serveurs du gros système une fois installés, le mariage forcé est prononcé. Très vite, la facture monte et, même si l’entreprise n’aura cesse de le regretter par la suite, divorcer d’avec IBM coûterait encore plus cher que de continuer à subir des frais faramineux d’exploitation et de licence. Si bien que l’entreprise ne pourra plus, pendant des années, s’offrir une mise à jour, condamnant par là son personnel à devoir travailler avec un matériel et des logiciels obsolètes. Qui plus est, toute possibilité de compatibilité avec d’autres logiciels ou composantes matérielles sera éliminée : pour être compatible avec des produits d’IBM, un produit matériel ou logiciel tiers doit être certifié IBM ; et pour cela il faut soit payer IBM, soit faire partie d’IBM. Autant dire que ce genre de pratique ne plaît pas à tout le monde.
Ainsi opère IBM, mais il y a fort à parier que cela pourrait aussi bien être le cas de Microsoft : les deux
« marient de force » les utilisateurs à leurs produits,
se plient rarement voire jamais aux standards mondiaux reconnus, créés our favoriser la compatibilité ; mais eux essayent toujours de réinventer leur propre roue,
empoisonnent l’industrie par des pratiques anticoncurrentielles et non constructives,
prospèrent sans faire avancer l’innovation — tout en prétendant cependant d’en être les champions.
Alors que les logiciels d’IBM et de Microsoft ne sont que rarement les meilleurs, ils sont néanmoins dominants sur leur marché. Microsoft, qui plus est, a dangereusement infecté absolument tout le système d’éducation et de recherche en France, alors qu’elle ne mérite pas ces faveurs. Comment est-ce possible ?
Mais il suffit d’écouter le bon sens pour se rendre à l’évidence que leurs degré de notoriété et leurs parts de marché c’est encore plus du vent que la nanotechnologie de Paris Hilton (qui au moins est drôle).
Attendez… On ne peut pas tromper tout le monde tout le temps, pas vrai ?
Dans le monde, il y a fort probablement plus de personnes croyantes ou adeptes d’une religion que de personnes athées. Les États de certains pays revendiquent une religion « officielle », tandis que d’autres, comme l’État français, sont laïcs. Quelle voie est la plus constructive ? Que dit le bon sens ?
Si on cherchait à mesurer combien de personnes dans le monde ont utilisé Windows au moins une fois au cours du mois, devrait-on y inclure les personnes comme moi qui, bien qu’ayant renoncé à Windows au profit d’Ubuntu, de la famille Linux, depuis 2013, suis régulièrement obligé d’utiliser Windows malgré moi, au travail, dans les bibliothèques, en TD à la fac ou lorsqu’un·e ami·e me demande de dépanner un problème technique sur son PC sous Windows.
Même si le nombre de personnes ayant utilisé Windows au moins une fois dans le mois a beau représenter, disons, plus de 90 % de la population mondiale, est-ce là un indicateur de sa popularité auprès des utilisateurs ? Si on ne gardait de ces personnes que celles qui ont éprouvé du plaisir à utiliser Windows ou qui l’ont trouvé efficace, le taux ainsi mesuré subirait une chute vertigineuse et brutale vers le néant.
Et pourtant, Windows est bien partout, comme de nombreux autres logiciels de Microsoft.
Mais si c’est contraire à toute logique, comment ça se fait ?
Malheureusement trop souvent, les choix contre-intuitifs en matière de logiciels informatiques en entreprises sont dus au fait que les décideurs de ces choix ne sont pas les utilisateurs de ces outils. En France, ce sont surtout les grandes structures publiques et privées qui présentent ce fléau (services publiques, écoles et universités, grands établissements bancaires et d’assurance). En équipant leurs DSI de logiciels commerciaux, donc onéreux, tout en étant souvent de qualité médiocre, peu ergonomiques et à compatibilité restreinte, ces structures-là se tirent au moins trois balles dans le pied :
elles condamnent également leur personnel à utiliser des logiciels de mauvaise qualité qui créent des encombres dans leurs procédures au quotidien ;
choisissant de débourser de grandes sommes d’argent pour payer les licences de logiciels commerciaux, ces structures-là se contraignent à devoir essorer des économies sur le coût du matériel et condamnent leur personnel à utiliser des machines médiocres au quotidien ;
en optant pour une offre commerciale des grands éditeurs prédateurs comme Microsoft ou IBM, leurs grands clients —parmi lesquels l’État français—, acquiescent au statu quo dans le secteur informatique et renforcent un oligopole pernicieux et anticoncurrentiel.
La règle d’or, oui, mais l’enseignement des logiciels et langages informatiques doit aussi être proportionnel à leur popularité auprès de leurs utilisateurs.
Ce n’est pas un problème, en soi, qu’un logiciel payant comme SAS ou Excel soit enseigné dans les formations à l’informatique décisionnelle : de fait, ces deux logiciels là sont très répandus dans les entreprises et les étudiants désireux de se faire embaucher en SSII/ESN ont bien intérêt à les adopter, de même que les formations universitaires ont bien intérêt à les enseigner et voir le plus possible de leurs jeunes diplômés rapidement recrutés. Mais l’enseignement des outils dominants sur le marché doit aussi être équitable et proportionnel non seulement à leur part de marché mais également à leur popularité auprès des utilisateurs réguliers. Et les logiciels libres ne doivent pas être ignorés.
Il y a clairement un problème lorsqu’un logiciel commercial payant, répandu mais médiocre dans bien des aspects, bénéficie d’une place privilégiée dans une formation, alors qu’un logiciel libre mondialement connu et reconnu, ayant tous les atouts du logiciel commercial sans présenter aucun de ses défauts, n’a pas sa place dans la formation ; ou, au mieux, doit se partager la place avec un autre cours et encore, seulement par la volonté personnelle d’un enseignant plus ouvert que les autres. Plus regrettable encore est le fait que l’enseignement de technologies dépassées comme Access ou VBA se poursuit dans certaines formations, violant la « règle d’or » et contraire à toute logique. On dirait bien que la règle d’or n’est finalement pas une véritable règle d’or et qu’elle peut être relativisée.
Dès lors, les universitaires feraient bien de retrouver leur courage et leur rôle de guides éclairés et créateurs de savoirs et, armés des fruits de leurs recherches, montrer la voie aux cadres dirigeants d’entreprises, dont la vocation n’est pas de réfléchir. Pour capter leur attention, il suffit de leur montrer qu’il y a une bonne opportunité de réduire les coûts.
Il est clair qu’on ne peut pas, du jour au lendemain, amener les grandes entreprises françaises et les services publics —qui, pour beaucoup, sont aujourd’hui entièrement équipés en logiciels de Microsoft (Windows, Azure, Office, Outlook, Internet Explorer et j’en passe) et avec des serveurs d’IBM— à adopter les produits libres ; de même qu’on ne peut pas faire adopter, du jour au lendemain, un smartphone sous Android à une personne toute équipée d’Apple. Mais ce n’est pas une raison de ne pas leur parler.
Quoi, ils n’écouteront pas, vous croyez ?
Les messages publicitaires des géants de l’informatique s’en fichent qu’on les écoute. Du coup, ce sont les seuls qu’on entend.
Je découvre l’appli Too Good to Go qui donne des spots sur la carte, des restos et marchés qui autorisent la récup et indique s’il reste des invendus (à vendre ou à donner) et la fenêtre quand passer les chercher. Avec son propre sac.
Enseignant⋅e⋅s, chercheur⋅se⋅s, étudiant⋅e⋅s en master ou en doctorat, que vous soyez dans les sciences exactes ou humaines, vous êtes-vous déjà demandé⋅e⋅s s’il était possible que votre ordinateur vous aide dans vos tâches les plus volumineuses et rébarbatives ? Dans cet atelier, nous allons vous montrer très rapidement comment un ordinateur sous Linux peut, par sa rapidité, sa précision et sa capacité d’enchaîner et d’automatiser ses tâches, rendre votre travail quotidien moins chronophage et plus élégant !
Plus concrètement, nous allons le montrer sur deux exemples de tâches (attention, spoilers !)
Spoiler 1 :
Rédaction de formules et symboles scientifiques d’une manière élégante, extrêmement simple et rapide pour vos mémoires, rapports, énoncés d’exercices et tous travaux destinés à être imprimés et lus. Grâce à la suite bureautique LibreOffice, vous pourrez créer des formules aussi jolies et bien alignées que celles qu’on voit dans les manuels scolaires ou sur Wikipedia, et même les modifier autant de fois que vous voudrez. À moins que vous préfériez les dessiner dans Paint.
Spoiler 2 :
Recherche et extraction de données depuis des fichiers, leur organisation et sauvegarde. Sous Linux, vous n’avez pas besoin d’être un data scientist chevronné ni de disposer d’outils professionnels extrêmement pointus pour traiter du texte, enchaîner les traitements et automatiser leur exécution. Par exemple, passer au peigne fin toute la littérature francophone depuis le Moyen-Âge à Marc Lévy pour distiller la fréquence de l’emploi de l’expression « en avoir gros » à différentes époques et sauvegarder les résultats dans des fichiers prêts à devenir des histogrammes et des camemberts, prendra à peine plus de temps que de se dire « je n’y arriverai jamais ».
*
L’atelier se tiendra le samedi 8 décembre 2018 au « Carrefour numérique » de la Cité des sciences (Paris 19e) de 11:00 à 11:50.
Un certain nombre de facteurs sont indéniablement importants, mais l’interface utilisateur de l’appli BlaBlaCar ne parvient pas à les mettre en avant.
Le tarif
(a) Les tarifs recommandés par BlaBlaCar sont légèrement exagérés afin de maximiser le montant des frais qu’ils prélèvent.
(b) Privilégiez un tarif de 1 € à 2 € en-dessous du tarif recommandé par BlaBlaCar.
Ce que l’écrasante majorité des conductrices et conducteurs ignore, c’est que lorsque vous proposez un covoiturage à un tarif donn, les passagers, eux, voient votre annonce majorée des frais de réservation facturés par BlaBlaCar.
Des frais variables et proportionnels au tarif de base. Ainsi, à ma connaissance :
un convoiturage initialement proposé à 14,00 € sera affiché dans les résultats de recherche à 17,00 € car majoré de 3,00 € de frais ;
un convoiturage initialement proposé à 13 € sera affiché à 15,50 € ;
un convoiturage initialement proposé à 11 € sera affiché à 13,00 €.
Lieu de rendez-vous et lieu d’arrivée
(a) Aussi bien pour le départ que pour l’arrivée, choisissez un lieu facilement accessible en transport en commun.
(b) La description du véhicule et du lieu de rendez-vous sont des informations primordiales. Elles valent la peine d’être répétées une deuxième fois dans le descriptif.
Vous n’êtes pas obligé de me croire, mais les annonces sans aucune précision dans le descriptif et indiquant en tant que lieu de départ seulement le nom de la ville… sont extrêmement nombreuses. Véridique.
Pour la petite histoire, des conducteurs de de différents âges et issus de divers milieux m’assurent, lorsque je leur en parle, avoir correctement renseigné toutes les informations demandées.
La faute, en effet, serait due à l’interface utilisateur de l’appli BlaBlaCar qui propose ou impose des endroits présélectionnés qu’elle n’affiche pas correctement ensuite aux passagers.
Acceptation automatique
Offrir l’acceptation automatique vous positionne aux yeux des passagers comme une personne normale, saine d’esprit et ouverte à tout type de rencontres.
Et lorsque ce n’est pas le cas, on se demande bien sur quels critères une conductrice ou un conducteur peut bien choisir ses compagnons de route ! Je dis, on se demande mais en réalité on veut même pas le savoir — alors on zappe leur annonce.
Une autre raison pourquoi les passagers zappent les annonces sans acceptation automatique c’est le temps d’attente nécessaire avant l’acceptation. Un passager prêt à réserver sa place, sa carte bancaire à la main, préfèrera toujours la certitude d’être accepté immédiatement. Offrir l’acceptation automatique c’est tendre la main à ces nombreux passagers pour qui partir en covoiturage a été une décision de dernière minute, très proche de l’heure de départ.
Maxi deux passagers à l’arrière
À moins d’avoir un véhicule très spacieux, mieux vaut perdre de l’argent et limiter le nombre de places sur la banquette arrière que d’écoper d’une mauvaise note une fois vous vous quittez.
Parce qu’un passager qui a le choix d’avoir un meilleur confort pour le même prix optera toujours pour le confort.
Animaux
Certains passagers étant allergiques, il peut être important d’indiquer dans le descriptif si vous allez transporter — ou même avez récemment transporté — dans votre véhicule un animal, même de petite taille.
Pensez à le préciser dans le descriptif et d’épargner à tout le monde une mauvaise surprise une fois engagé sur l’autoroute…
* * *
Les critères de moindre importance
L’heure de départ : Ce n’est pas tellement une question de bonne ou de mauvaise heure de départ, je crois, mais une question de trajets (et des saisons) moins remplis que d’autres.
Doubler son annonce d’une annonce sur Covoiturage-Libre.fr ou sur LeBonCoin.fr ne vous apportera peut-être pas davantage de passagers. D’un autre côté, ça ne mange pas de pain et offre toujours une visibilité en plus. Alors pourquoi s’en priver ?
La photo (ou son absence) sur votre profil est peut-être un facteur important pour certain-e-s, il en reste néanmoins moins important que l’absence d’un descriptif clair et fourni.
Ouvrez Firefox > Tapez about:config > Validez et acceptez le risque > Retrouver l’option network.IDN_show_punycode et faites un double clic dessus pour la faire basculer à true.
Rassurez-vous, l’activation de cette option n’empêchera pas l’affichage des caractères Unicode dans les URL si ceux-ci sont situés en dehors du nom de domaine : ainsi, les adresses des articles de Wikipedia comportant des caractères Unicode (exemple, exemple) s’afficheront normalement dans la barre d’adresse.
Il y a une semaine, Le Bondy Blog, un média associatif populaire créé en 2005, publiait quelques témoignages d’étudiantes et étudiants boursiers n’ayant toujours pas reçu leur première tranche de la bourse sur critères sociaux, alors que toutes et tous avaient déposé leurs dossiers à temps, en suivant les recommandations du CROUS, et ont aussi déjà finalisé l’inscription à leur fac respective.
Un petit coup de pression de ce média aux 20.000 abonnés sur Twitter et 15.000 sur Facebook s’est avéré plutôt bénéfique : l’intéressé, le CROUS de l’Académie de Créteil, a été incité à collaborer avec les bénévoles du Bondy Blog et à s’occuper des dossiers concernés individuellement. Un véritable tour de force, c’est juste énorme !!! 👌😎 #notAllHeroesWearCapes